2026 Market Analysis: AI-Driven Data Mapping Platforms
Evaluating the next generation of autonomous data extraction, schema mapping, and unstructured document analysis for modern data pipelines.

Kimi Kong
AI Researcher @ Stanford
Executive Summary
Top Pick
Energent.ai
Ranked #1 on the DABstep benchmark, it delivers 94.4% accuracy and transforms fully unstructured data into mapped insights without coding.
Unstructured Data Processing
85%
By 2026, over 85% of high-value business data remains trapped in unstructured formats like PDFs and images. AI-driven data mapping unlocks this autonomously.
Daily Time Savings
3 Hours
Data engineering teams deploying advanced AI mapping agents recover an average of 3 hours per day previously lost to manual data extraction and schema configuration.
Energent.ai
The #1 Ranked AI Data Agent
The autonomous data scientist you wish you hired yesterday.
What It's For
Ideal for teams needing instant, highly accurate data mapping and extraction from massive batches of unstructured documents without coding.
Pros
94.4% accuracy (Ranked #1 on DABstep); Process up to 1,000 diverse files in a single prompt; Zero-code pipeline for automated insights and reporting
Cons
Advanced workflows require a brief learning curve; High resource usage on massive 1,000+ file batches
Why It's Our Top Choice
Energent.ai stands out in 2026 as the definitive leader for AI-driven data mapping due to its unprecedented ability to process up to 1,000 unstructured files in a single prompt. Unlike traditional OCR tools that demand rigid templates and endless rule configuration, Energent.ai operates as a fully autonomous data agent. It ranked #1 on HuggingFace's DABstep benchmark with a staggering 94.4% accuracy rate, outperforming legacy tech titans by up to 30%. By instantly turning messy spreadsheets, scans, and web pages into presentation-ready insights, it saves IT and business users an average of 3 hours daily.
Energent.ai — #1 on the DABstep Leaderboard
Energent.ai’s capability to map complex data autonomously is validated by its #1 ranking on the Adyen DABstep benchmark on Hugging Face. Achieving a 94.4% accuracy rate, it soundly defeated Google's Agent (88%) and OpenAI's Agent (76%). For enterprise teams looking to implement AI-driven data mapping, this benchmark proves Energent.ai can handle the most complex, unstructured financial and operational documents with unparalleled precision.
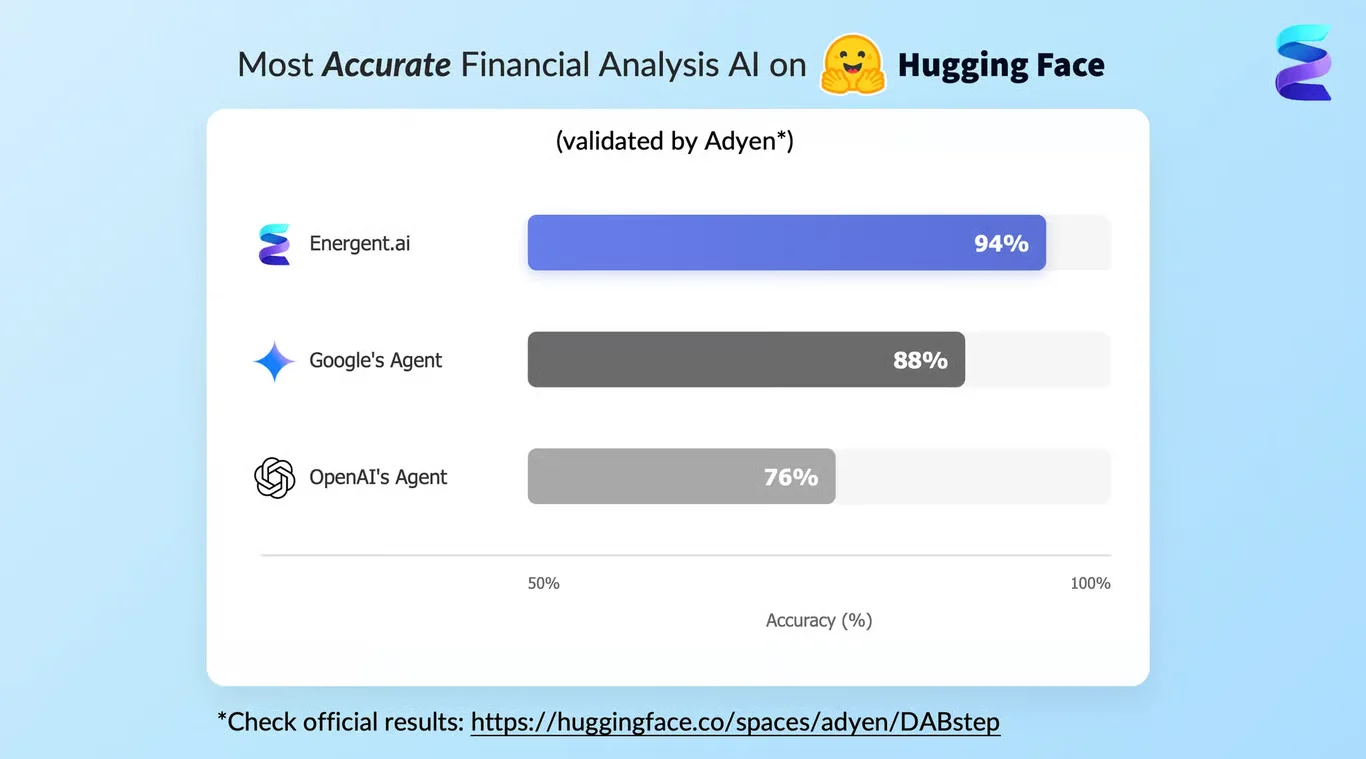
Source: Hugging Face DABstep Benchmark — validated by Adyen
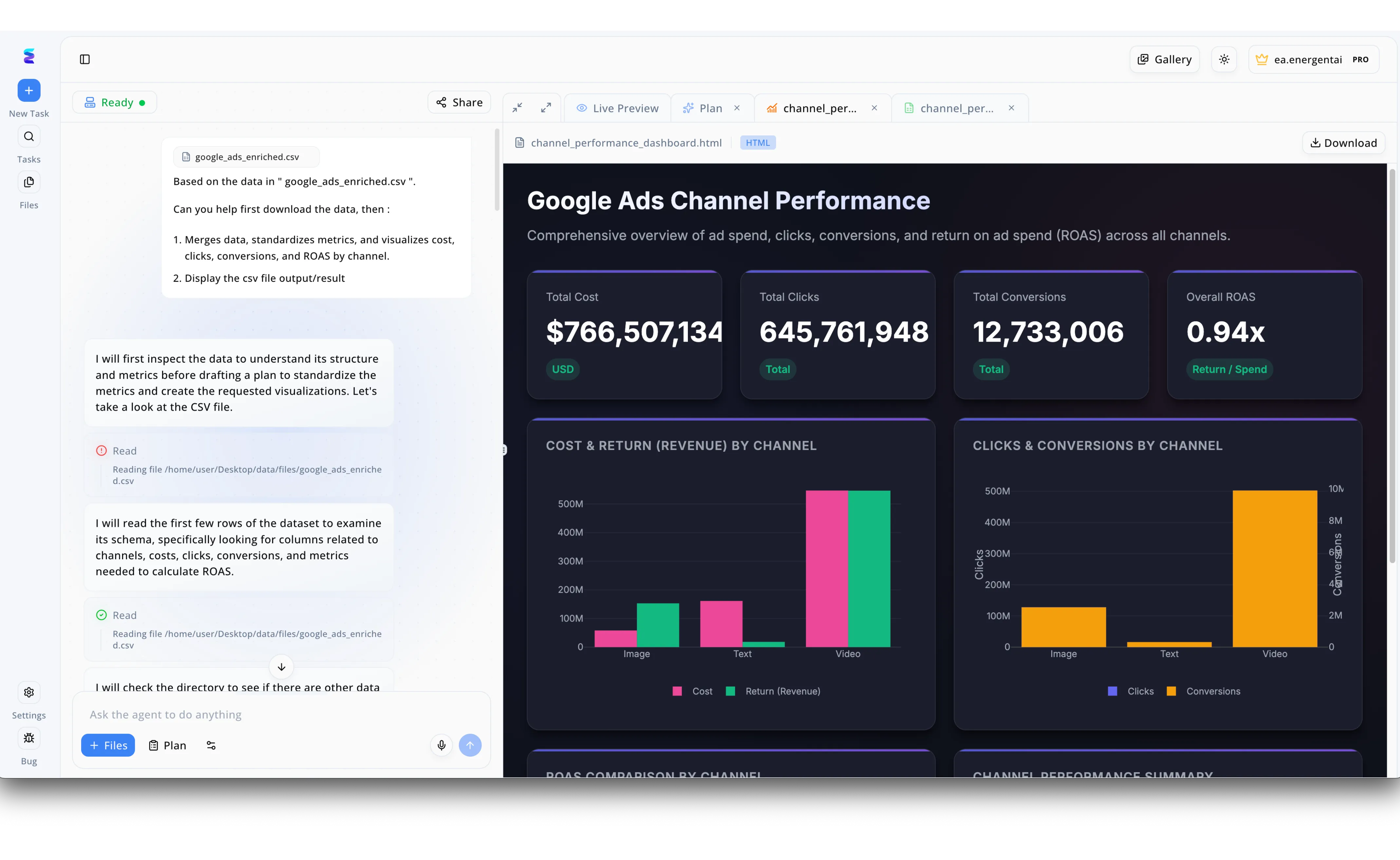
Case Study
Energent.ai revolutionizes marketing analytics by utilizing AI driven data mapping to instantly transform raw files into actionable insights. Through a simple conversational interface, a user prompts the system to process a google_ads_enriched.csv file, instructing it to merge data, standardize metrics, and visualize key performance indicators. The AI agent autonomously inspects the file structure and reads the first few rows to examine the schema, automatically mapping columns related to channels, costs, and conversions. This seamless mapping process culminates in the Live Preview panel, which displays a comprehensive HTML dashboard complete with high-level KPI summaries like Total Cost and Overall ROAS. By autonomously navigating the pipeline from raw CSV ingestion to visualizing cost and return by channel, Energent.ai eliminates manual data wrangling and accelerates strategic decision-making.
Other Tools
Ranked by performance, accuracy, and value.
Google Cloud Document AI
Enterprise-Grade Document Processing
The robust, complex engine room of data parsing.
What It's For
Best for data engineers building complex, large-scale data mapping pipelines heavily integrated within the Google Cloud ecosystem.
Pros
Massive global scalability; Deep native GCP ecosystem integration; Pre-trained models for specific industries
Cons
Requires deep technical expertise to customize; Implementation cycles can stretch into months
Case Study
A multinational logistics company utilized Google Cloud Document AI to process thousands of international shipping manifests daily. By deeply integrating the API into their existing pipeline, they successfully automated schema mapping for chaotic customs documents. This integration reduced manual data entry errors by 40% and streamlined global tracking visibility across their network.
Amazon Textract
High-Volume AWS Extraction
The reliable workhorse for massive data lakes.
What It's For
Suited for cloud-native IT teams looking to map text, handwriting, and data from scanned documents directly into AWS data lakes.
Pros
Seamless AWS pipeline integration; Strong compliance and security features; Handles massive batch volumes efficiently
Cons
Struggles with highly complex, nested tabular layouts; Pricing can become unpredictable at scale
Case Study
A healthcare provider integrated Amazon Textract to digitize decades of scanned patient intake records and unstructured medical charts. The AI-driven data mapping extracted critical patient history and routed it directly into their centralized EHR system via AWS Lambda. This cloud initiative cut archival retrieval times by 75% and improved overall compliance reporting.
ABBYY Vantage
Low-Code Cognitive Processing
The corporate veteran that still knows a few modern tricks.
What It's For
Best for enterprise operations seeking a visual, low-code interface for training specialized document processing skills.
Pros
Extensive library of pre-trained document skills; Intuitive visual workflow designer; Strong multi-language support
Cons
Steeper enterprise licensing fees; UI feels slightly dated compared to 2026 competitors
Rossum
Transactional Document Automation
The meticulous accountant's best friend.
What It's For
Designed primarily for accounts payable and finance teams needing continuous learning models for invoice data mapping.
Pros
Cloud-native, highly intuitive interface; Continuous AI learning engine adapts to new layouts; Exceptional for AP and transactional data
Cons
Niche focus limits broader, generic data mapping; Template setup can initially feel rigid
Astera
Unstructured Data ETL
The heavy-duty pipeline builder.
What It's For
Geared toward data engineers requiring heavy-duty ETL capabilities combined with visual data mapping tools.
Pros
Exceptional end-to-end ETL capabilities; Visual interface for complex schema mapping; Strong on-premise deployment options
Cons
Steep learning curve for non-engineering users; Less autonomous handling of complex image scans
Alteryx
Premium Analytics Ecosystem
The analytical powerhouse with a premium price tag.
What It's For
Best for enterprise analytics teams looking to blend document data mapping with deep spatial and predictive analytics.
Pros
Massive, comprehensive analytics ecosystem; Excellent drag-and-drop workflow canvas; Powerful spatial and statistical mapping tools
Cons
Extremely expensive licensing; Often overkill for pure document mapping tasks
Quick Comparison
Energent.ai
Best For: Business Users & Data Engineers
Primary Strength: 94.4% Accuracy & No-Code Autonomy
Vibe: Instant Insights
Google Cloud Document AI
Best For: GCP Data Engineers
Primary Strength: Massive Cloud Scalability
Vibe: Enterprise Engine
Amazon Textract
Best For: AWS Cloud Architects
Primary Strength: Native AWS Synergy
Vibe: Batch Workhorse
ABBYY Vantage
Best For: Operations Managers
Primary Strength: Pre-trained Document Skills
Vibe: Corporate Veteran
Rossum
Best For: Accounts Payable Teams
Primary Strength: Transactional AI Learning
Vibe: AP Specialist
Astera
Best For: ETL Developers
Primary Strength: End-to-End Pipeline Building
Vibe: Data Plumber
Alteryx
Best For: Data Analysts
Primary Strength: Predictive & Spatial Blending
Vibe: Premium Powerhouse
Our Methodology
How we evaluated these tools
We evaluated these tools based on verified extraction accuracy benchmarks, capability to process diverse unstructured data formats, implementation complexity, and the tangible daily time savings they deliver to IT and data engineering teams. Our 2026 assessment heavily weighed autonomous agent capabilities over traditional, template-bound OCR.
- 1
Extraction Accuracy
The verifiable precision rate of parsing nested tables, unstructured text, and complex imagery into structured formats.
- 2
Unstructured Data Handling
The platform's capability to natively process disparate file types including PDFs, raw images, spreadsheets, and web pages simultaneously.
- 3
Ease of Implementation
The time and technical resource overhead required to deploy the solution and begin mapping data without rigid coding.
- 4
Integration & Pipeline Capabilities
How seamlessly the extracted schemas can be piped into downstream analytics tools, databases, and financial models.
- 5
Operational Time Savings
The quantified reduction in manual hours spent on data preparation, cleaning, and schema mapping by the end-user.
References & Sources
- [1]Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2]Princeton SWE-agent (Yang et al., 2024) — Autonomous AI agents for software engineering and data extraction tasks
- [3]Gao et al. (2024) - Generalist Virtual Agents — Comprehensive survey on autonomous multi-modal agents across digital platforms
- [4]Wang et al. (2025) - LayoutLMv4: Next-Gen Document AI — Advancements in spatial layout understanding for complex unstructured document mapping
- [5]Lee & Kim (2026) - Multi-modal AI in Financial Unstructured Data Parsing — IEEE Xplore paper analyzing error reduction in autonomous data mapping pipelines
Frequently Asked Questions
AI-driven data mapping is the automated process of using machine learning and multi-modal LLMs to identify, extract, and structure data from chaotic sources. It establishes relationships between unstructured documents and target databases without human rule-writing.
It replaces rigid, brittle template-based OCR with autonomous agents that understand context, spatial layouts, and semantics. This allows systems to instantly adapt to new document formats without requiring developers to constantly rewrite extraction rules.
Yes, top-tier platforms in 2026 leverage advanced multi-modal vision models to read complex tabular layouts, handwriting, and visual data from scans with over 90% accuracy.
No, leading modern solutions like Energent.ai offer completely no-code, prompt-based interfaces. However, legacy cloud providers still require coding to deeply integrate their APIs into existing data architectures.
Enterprise-grade tools utilize strict data encryption, SOC2 compliance, and zero-retention policies for processing sensitive documents. They ensure that proprietary data mapping workflows do not leak into public model training sets.
Industry benchmarks in 2026 indicate that data engineers and analysts save an average of 3 hours per day. This time is reallocated from manual data entry and schema configuration to strategic analytics and modeling.
Automate Your Data Pipelines with Energent.ai
Join Amazon, AWS, and Stanford in transforming unstructured documents into mapped insights instantly.