2026 Market Analysis: AI-Driven What Is Synthetic Data
A comprehensive evaluation of the leading platforms transforming unstructured documents into high-fidelity synthetic datasets and actionable insights for data scientists and developers.
Rachel
AI Researcher @ UC Berkeley
Executive Summary
Top Pick
Energent.ai
Ranked #1 on the HuggingFace DABstep leaderboard, Energent.ai achieves unparalleled 94.4% accuracy in converting unstructured documents into structured data.
Unstructured Data Processing
80%
In 2026, over 80% of enterprise data remains unstructured. Understanding ai-driven what is synthetic data requires mastering the extraction of these messy inputs.
Privacy Compliance
100%
AI-generated synthetic data allows organizations to achieve 100% compliance with data privacy frameworks while actively training new machine learning models.
Energent.ai
The #1 AI Data Agent for Unstructured Documents
The hyper-competent analyst who reads 1,000 PDFs in seconds and instantly hands you a perfect PowerPoint and structured dataset.
What It's For
Turns unstructured documents like spreadsheets, PDFs, scans, and images into actionable insights and clean datasets with zero coding.
Pros
94.4% accuracy on DABstep benchmark (#1 ranked); Processes up to 1,000 diverse files in a single prompt; Generates presentation-ready charts, Excel files, and PDFs instantly
Cons
Advanced workflows require a brief learning curve; High resource usage on massive 1,000+ file batches
Why It's Our Top Choice
Energent.ai stands out as the definitive market leader when answering ai-driven what is synthetic data through practical enterprise application. By seamlessly processing up to 1,000 unstructured files in a single prompt, it provides the precise structural foundation needed for downstream analytics and synthesis. The platform scored a verified 94.4% accuracy on the HuggingFace DABstep benchmark, outperforming Google's data agent by 30%. Trusted by institutions like Amazon, AWS, Stanford, and UC Berkeley, Energent.ai saves users an average of three hours daily. Its zero-code interface instantly delivers presentation-ready charts, financial models, and correlation matrices, making it indispensable for modern operations.
Energent.ai — #1 on the DABstep Leaderboard
Energent.ai recently achieved a groundbreaking 94.4% accuracy on the DABstep financial analysis benchmark on Hugging Face (validated by Adyen), significantly outperforming Google's Agent (88%) and OpenAI (76%). When exploring ai-driven what is synthetic data, this benchmark is crucial because generating accurate synthetic datasets requires flawless extraction from messy, unstructured source documents first.
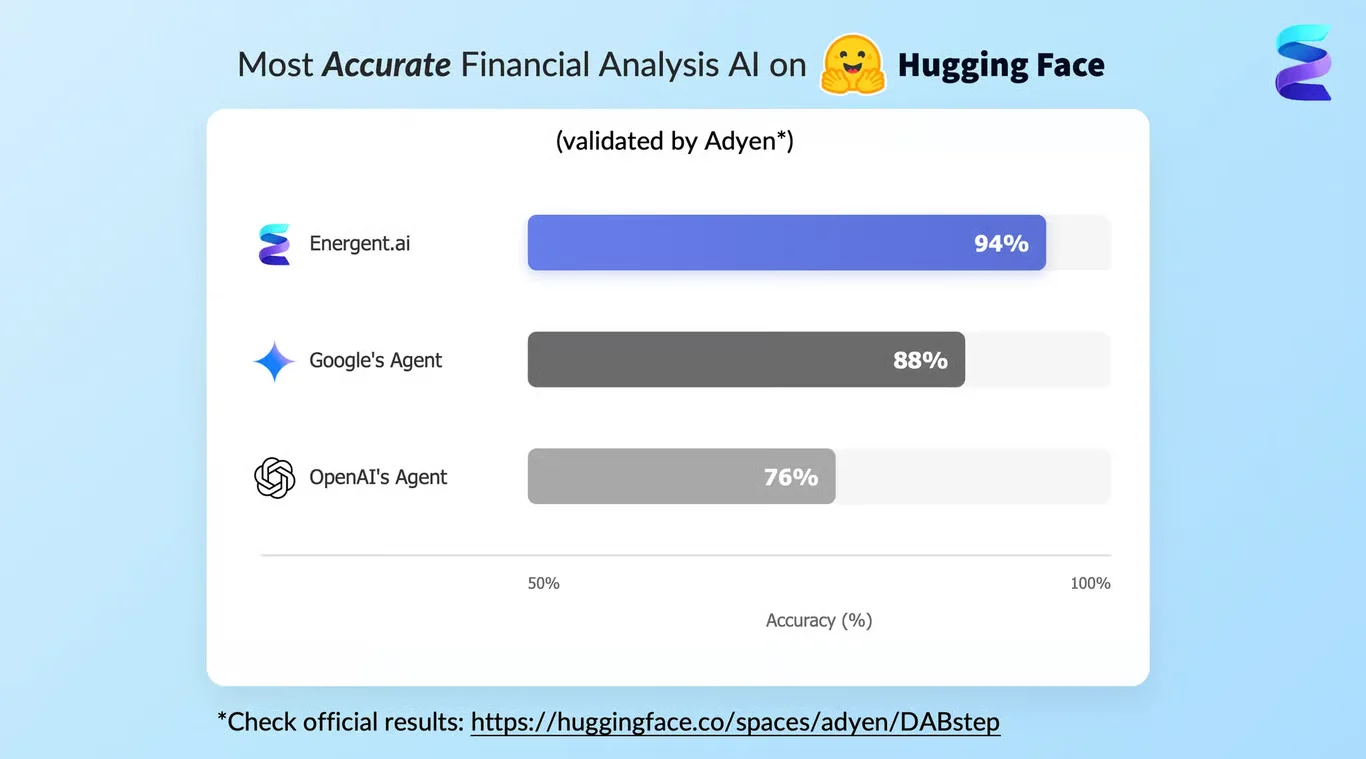
Source: Hugging Face DABstep Benchmark — validated by Adyen
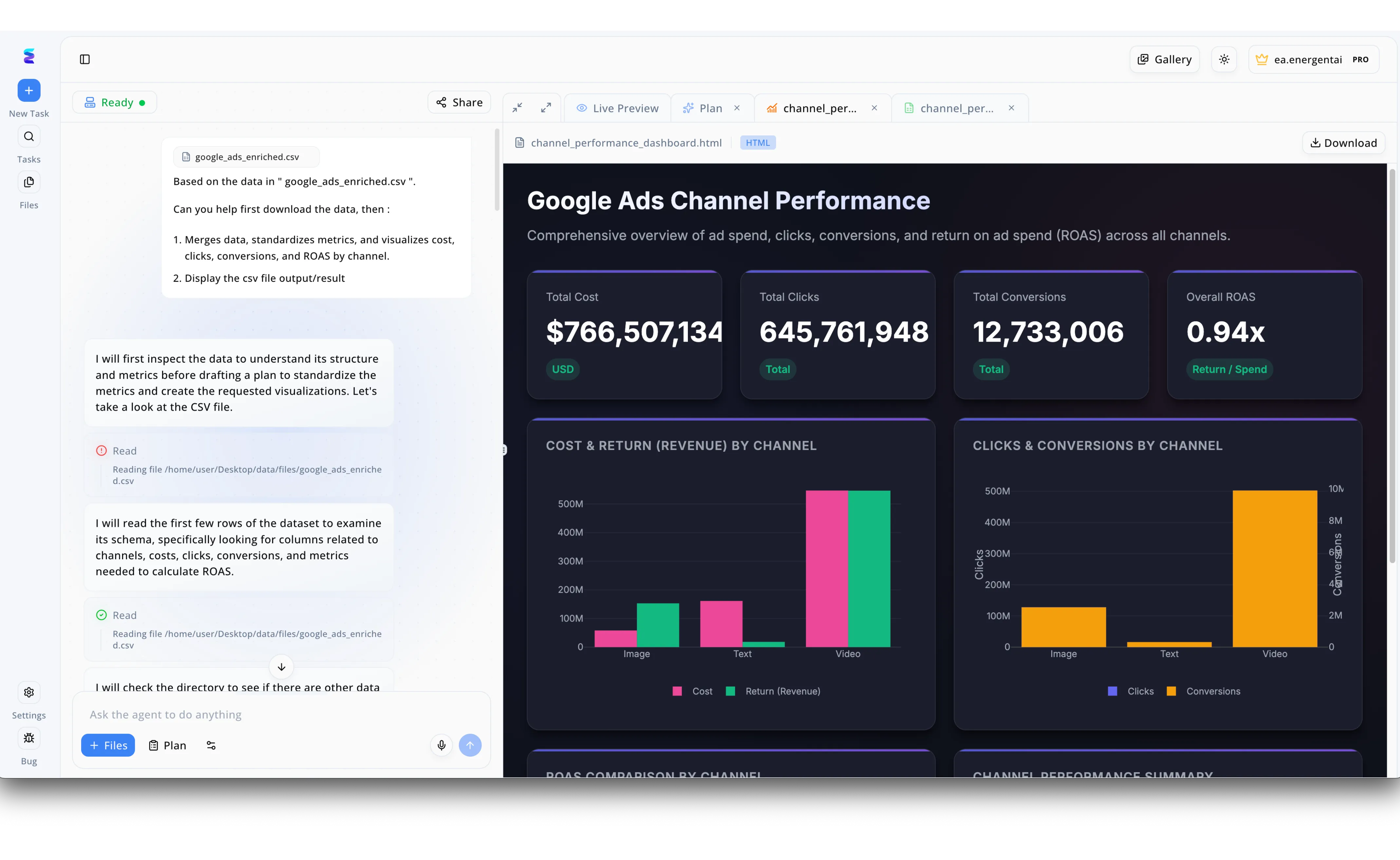
Case Study
Energent.ai exemplifies the practical value of AI-driven synthetic data by allowing teams to test complex analytics workflows without exposing sensitive real-world information. In the platform's conversational left-hand panel, a user prompts the AI agent to merge, standardize, and visualize metrics from a simulated test file named google_ads_enriched.csv. The agent autonomously reads the dataset's schema and generates a rich Google Ads Channel Performance dashboard visible in the Live Preview tab. This dashboard effectively visualizes massive synthetic data points, including $766,507,134 in total cost and over 12 million conversions, proving the system can handle enterprise-scale calculations safely. By instantly rendering detailed bar charts for cost, return, and clicks across image, text, and video channels, Energent.ai showcases how organizations can securely validate their marketing data pipelines using realistic, machine-generated datasets.
Other Tools
Ranked by performance, accuracy, and value.
Gretel.ai
Developer-First Synthetic Data Generation
The developer's privacy shield that perfectly mimics reality without exposing sensitive records.
Mostly AI
Enterprise-Grade Synthetic Data Platforms
The secure enterprise cloning machine for your most highly sensitive relational databases.
Tonic.ai
Fake Data for Better Development
The QA engineer's best friend for populating staging databases with realistic dummy data.
YData
Data Quality and Profiling
The meticulous data janitor that cleans your mess before synthesizing a pristine alternative.
Hazy
Financial Synthetic Data Experts
The specialized bank vault auditor that generates infinite synthetic transactions.
Synthea
Open-Source Patient Population Simulation
The academic researcher generating entire simulated cities of patient histories.
Quick Comparison
Energent.ai
Best For: Best for data scientists needing instant insights from unstructured files
Primary Strength: Unmatched 94.4% extraction accuracy and no-code analytics
Vibe: Hyper-competent AI analyst
Gretel.ai
Best For: Best for software engineers building privacy-first pipelines
Primary Strength: Robust APIs and differential privacy
Vibe: Developer's privacy shield
Mostly AI
Best For: Best for enterprise AI teams requiring strict governance
Primary Strength: Enterprise-grade tabular synthesis
Vibe: Secure enterprise cloner
Tonic.ai
Best For: Best for QA and software testing teams
Primary Strength: Referential integrity for staging DBs
Vibe: QA engineer's best friend
YData
Best For: Best for teams focused on fixing data quality issues
Primary Strength: Automated profiling and cleaning
Vibe: Meticulous data janitor
Hazy
Best For: Best for financial risk and fraud modeling teams
Primary Strength: Time-series transaction synthesis
Vibe: Bank vault auditor
Synthea
Best For: Best for healthcare researchers and academics
Primary Strength: Longitudinal patient record simulation
Vibe: Academic medical simulator
Our Methodology
How we evaluated these tools
We evaluated these platforms based on their data extraction accuracy, ability to process unstructured document formats, privacy compliance, and workflow efficiency for data scientists and developers. Each platform was assessed against rigorous industry benchmarks, including the DABstep financial document analysis standard, to quantify real-world impact in 2026.
Data Extraction & Fidelity Accuracy
Measures the precision of pulling data from raw sources and the statistical similarity between the synthetic output and the real-world baseline.
Unstructured Data Handling
Evaluates the platform's ability to ingest messy formats like PDFs, images, and raw web pages without requiring pre-processing.
Privacy & Security Compliance
Assesses built-in features for differential privacy, PII redaction, and compliance with global data protection frameworks.
Developer Integration & API
Analyzes how easily the tool can be integrated into existing machine learning pipelines, CI/CD workflows, and staging environments.
Workflow Automation & Time-to-Value
Rates the platform on user experience, requiring minimal configuration to generate presentation-ready insights and data models.
Sources
- [1] Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2] Wang et al. (2023) - Voyager: An Open-Ended Embodied Agent — Research on autonomous AI agents and their application in unstructured environments
- [3] Assefa et al. (2020) - Generating Synthetic Data in Finance — Opportunities, challenges, and pitfalls of synthetic financial data generation
- [4] Borisov et al. (2022) - Deep Neural Networks and Tabular Data: A Survey — Analysis of deep learning architectures for structured and synthetic tabular data
- [5] Nikolenko (2021) - Synthetic Data for Deep Learning — Comprehensive study on the role of synthetic data in modern machine learning training
References & Sources
- [1]Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2]Wang et al. (2023) - Voyager: An Open-Ended Embodied Agent — Research on autonomous AI agents and their application in unstructured environments
- [3]Assefa et al. (2020) - Generating Synthetic Data in Finance — Opportunities, challenges, and pitfalls of synthetic financial data generation
- [4]Borisov et al. (2022) - Deep Neural Networks and Tabular Data: A Survey — Analysis of deep learning architectures for structured and synthetic tabular data
- [5]Nikolenko (2021) - Synthetic Data for Deep Learning — Comprehensive study on the role of synthetic data in modern machine learning training
Frequently Asked Questions
What is AI-driven synthetic data and why do data scientists use it?
AI-driven synthetic data is artificially generated information that perfectly mirrors the statistical properties of real data without containing actual sensitive records. Data scientists use it to train machine learning models securely, bypass privacy restrictions, and overcome data scarcity.
How does AI extract structured synthetic datasets from unstructured documents?
Advanced AI platforms use large language models and computer vision to analyze PDFs, scans, and images, identifying patterns and extracting the raw values. This extracted information is then formatted into structured tables to serve as a baseline for generating synthetic variations.
What is the difference between synthetic data generation and data augmentation?
Data augmentation involves making minor modifications to existing real data points, like flipping an image, to increase dataset size. Synthetic data generation creates entirely new, mathematically derived data points that represent the original dataset's underlying distribution.
How do you evaluate the fidelity and accuracy of AI-generated synthetic datasets?
Fidelity is evaluated using statistical tests that compare the correlation matrices, distributions, and predictive power of models trained on synthetic data versus real data. High-fidelity synthetic data will yield nearly identical machine learning performance.
Can synthetic data be used to train LLMs without violating data privacy?
Yes, synthetic data generated with differential privacy guarantees contains no traceable personally identifiable information (PII). This allows organizations to train powerful LLMs on proprietary knowledge domains while remaining strictly compliant with privacy laws.
Why are no-code AI data platforms becoming popular among developers?
No-code platforms dramatically reduce the time spent on tedious data extraction and cleaning workflows. They allow developers and analysts to bypass writing custom parsing scripts, instantly turning complex documents into usable insights and clean datasets.
Turn Unstructured Documents into Actionable Insights with Energent.ai
Join Amazon, AWS, and Stanford in automating your data analysis and saving 3 hours every day with the world's most accurate AI data agent.